

Cookies Notice
This site uses cookies to deliver services and to analyze traffic.
📣 Guardian Agent: Guard AI-generated code

Unified risk and vulnerability management across application, infrastructure, and code quality scanners, with code-to-runtime actionable context
Automated security controls validation and assurance based on your organization’s SDLC policies, with actionable context from your CMDB

Risk Graph policy engine and developer’s guardrails at every phase: design, development (pull request), and delivery (build/deploy)

Modern applications generate a tremendous amount of runtime traffic across services, environments, and teams. Security and platform engineers alike are often left asking the same question: Where in the code is this coming from—and who owns it?
In his talk at PyData Tel Aviv, Yosi from Apiiro’s data science team walks through a real-world machine learning solution that answers this question. His team built a scalable system to match runtime HTTP traffic (what sniffing tools see in production) to the actual code APIs that handle it. This capability helps engineers prioritize risk and focus remediation efforts where they matter most.
Let’s dive in.
There are two key definitions that define the foundation of the problem. First, there are endpoints–HTTP requests observed at runtime by sniffing tools, such as /api/v1/user. Then, there are code APIs–the actual controller functions or methods in the source code that handle those requests.
Matching these two is critical for a couple of reasons. From a security perspective, when a vulnerability is discovered in a runtime endpoint, engineers need to know who owns the underlying code in order to fix it. And from an operational standpoint, if an endpoint is active in traffic and can be tied back to a specific repository, that’s a strong signal that the repository is deployed and should be monitored.
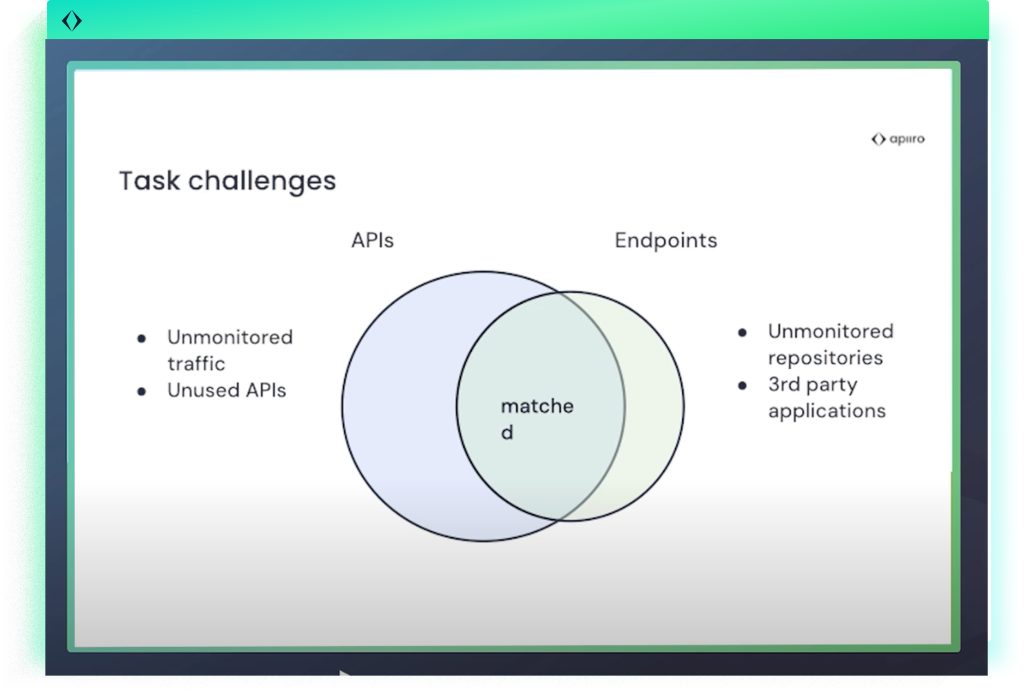
But making that connection isn’t simple. Routes often don’t match exactly, especially when there’s rerouting infrastructure or API gateways involved. In some cases, traffic that looks different—like /eu/user versus /us/user—may actually be handled by the same code, but sniffing tools report them as separate endpoints. To complicate things further, not all properties of a request, such as body content or query parameters, are clearly defined in code. And finally, many endpoints and APIs may never match at all—either because traffic wasn’t captured or because the code in question isn’t currently deployed.
The team explored several early approaches to the matching problem, starting with heuristics. These rule-based methods compared routes and parameters to identify potential matches. While they were quick to implement, they couldn’t handle ambiguity well and broke down at scale.
They also evaluated generative large language models like ChatGPT. Although promising in theory, these models posed serious data privacy concerns—customer code couldn’t be sent to third-party services. Even open-source versions lacked the accuracy needed, and the cost of running them at scale was another barrier.
Another idea was to feed all endpoints and APIs into a model and let it determine the matches. But this quickly ran into technical limits. The sheer volume of input data exceeded what language models could reasonably process, making this approach impractical.
Instead of treating this as a “find-the-match” problem, the team reframed it as a classification problem: Given an endpoint and a candidate API, is this a match?
Stage 1: Candidate Retrieval (Down to 15)
For each endpoint, the system first narrows down potential matches to a set of 15 candidates using a statistical similarity function (best_match_25). This includes:
This fast filtering dramatically reduces the search space—from tens of thousands of possible APIs to just 15.
Stage 2: BERT-Based Ranking (Pick the Best Match)
Each endpoint is then paired with each of its 15 candidates and passed to a BERT model—a lightweight, open-source transformer well-suited to classification of text pairs. The BERT model assigns a relevance score for each candidate pair.
But there’s a catch: BERT sometimes gives lower scores to the correct match because it treats common tokens (like api, user) the same as more unique ones (vip_gift). To address this, the team added TF-IDF features to highlight how rare and meaningful certain terms are across the dataset.
The final classifier combines BERT scores and TF-IDF weights using a linear regression layer to produce the most likely match.
The system now runs periodically for customers and delivers measurable results:
There are four main insights from this talk. First, reframing the problem as a classification task rather than a direct matching task makes it more manageable. Second, a two-stage approach—narrowing down candidates before applying a model—strikes the right balance between scalability and accuracy. Third, using techniques like TF-IDF helps restore important contextual signals that models like BERT might overlook. And finally, choosing the right model matters: BERT is lightweight, efficient, and well-suited for this kind of pairwise classification. Apiiro’s approach doesn’t just answer “who owns this code?”—it enables teams to act quickly and confidently when vulnerabilities appear in production.
Interested in the full 20-minute talk? Watch the video here.

This site uses cookies to deliver services and to analyze traffic.